大家好!我们刚刚在 Asahi Linux 的 x86/x86-64 模拟技术栈上发布了一个非常酷的更新, 我想分享一下我们一直在做的工作. 从今天开始, 非游戏应用程序现在可以使用了!
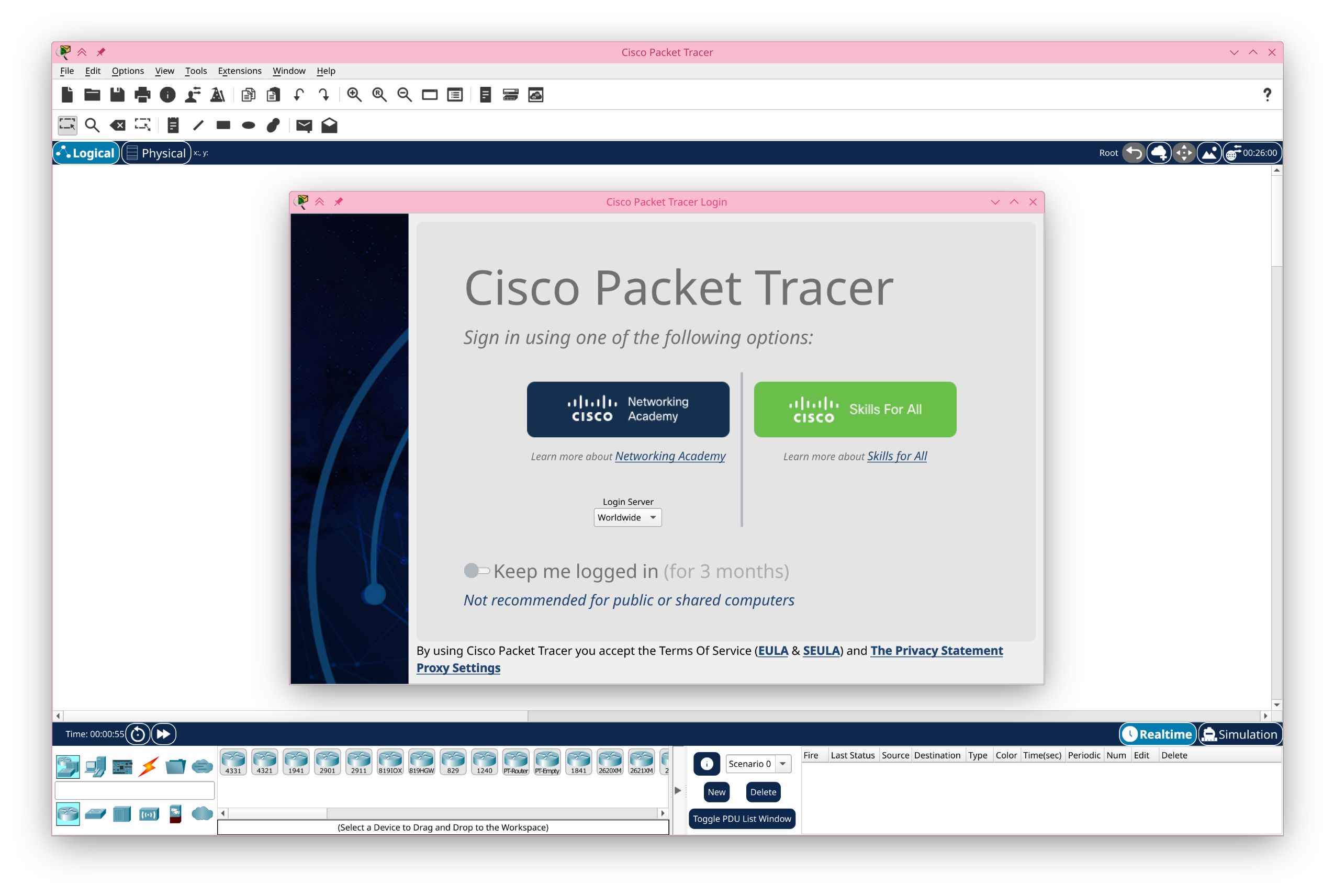
虚拟机中的原生图形
正如你可能还记得我们之前的博客文章, Asahi Linux 在由 muvm 驱动的 microVM 中运行所有 x86/x86-64 应用程序. 我们如何能够在没有硬件 GPU 直通的情况下, 在真实的虚拟机中以接近原生性能运行游戏呢?
在 AMD/Intel 系统上(实际上, 在 Apple Silicon 的 macOS 上也是如此), GPU 虚拟化一直是受限的. 你可以选项要么是直通硬件 GPU, 要么是使用 API 级别的 GPU 半虚拟化. 直通硬件 GPU 将 GPU 设备完全分配给客户机, 这意味着它将其视为“真实”的 GPU 设备. 这适用于所有具有该 GPU 真实驱动程序的客户操作系统, 并且具有原生性能, 但这意味着 GPU 被客户机独占, 因此你无法与主机共享它或将客户机和主机窗口集成在一个屏幕上. 与此同时, API 级别的 GPU 半虚拟化本质上是将来自客户机的 OpenGL、Vulkan 或 Metal 命令发送到主机, 因此由主机的 GPU 驱动程序栈处理. 这需要客户机中“通用”的半虚拟化 GPU 驱动程序, 并且由于所有高级 GPU 绘图命令必须跨越客户机到主机的边界并在主机上处理, 因此速度比原生 GPU 使用慢得多. 这就是 GPU 虚拟化在 macOS 上工作的方式. 一些 GPU(例如 最近的 Nvidia GPU)支持带有硬件虚拟化支持的真实共享, 但这尚未上游化, 并且需要硬件支持, 而 Apple GPU 并不具备.
但如果有更好的方法呢?事实证明, 确实有!引入 DRM 原生上下文.
这个概念非常简单: 与其在客户机上运行整个 GPU 驱动程序栈并直通硬件 GPU(不共享), 或者在主机上运行整个 GPU 驱动程序栈并通过高级 API(速度慢)通信, 为什么不尝试一下折中的方案呢?通过DRM 原生上下文, 在主机上运行 GPU 内核驱动程序, 在客户机上运行 GPU 用户空间驱动程序(Mesa), 并将内核 UAPI 接口从客户机传递到主机.
这让我们兼得鱼与熊掌: 由于 GPU 用户空间驱动程序在客户机中运行, 它们可以像驱动真实的硬件 GPU 一样以完整性能运行. 由于 GPU 内核驱动程序在主机中运行, 它可以在主机应用程序和客户机应用程序之间共享. 一个简化的渲染操作可能是这样的:
- 该应用程序发出 GL 或 Vulkan 绘制命令在屏幕上绘制内容. 一个游戏每帧可能执行数千个这样的命令.
- 客户机中的用户空间 Mesa 驱动程序接收这些命令并将其转换为 GPU 命令结构体. 这些结构体被直接写入事先被驱动程序使用 virtio-gpu 协议直接从主机映射而来的 GPU 内存, 因此其速度与原生运行一样快.
- 该应用程序刷新绘制流或以其他方式请求 GPU 开始渲染.
- 用户空间的 Mesa 驱动程序准备整体渲染信息, 就像在主机上运行一样自然.
- Mesa 然后将命令封装在一个 virtio-gpu 执行缓冲区中, 该缓冲区包含将命令传递给主机所需的信息.
- 该命令最多只有一两千字节的数据, 通过客户机内核 virtio-gpu 驱动程序传输到主机虚拟机显示器.
- VMM 接收命令并将其传递给 virglrenderer, 后者解包本地 UAPI GPU 命令结构.
- virglrenderer 向主机 GPU 内核驱动程序传递
ioctl()的命令. - 主机 GPU 内核驱动程序将命令发送到 GPU.
在主机上原生渲染的过程完全相同, 只是省略了第 5 到第 7 步(在第 8 步中, Mesa 将直接发出 ioctl() ). 因此, 开销非常小, 因为额外的客机通信只涉及少量数据, 而不必通过整个 GL 或 Vulkan 命令流. 这也意味着我们可以运行与原生相同的驱动程序, 因此我们知道 GPU 功能应该完全相同, 具有相同的 GPU 驱动程序质量和兼容性.
安全性和隔离性如何?从主机内核驱动的角度来看, 客户机上的每个进程都被视为一个独立的 GPU 进程(更具体地说, 每当客机进程打开虚拟 GPU 设备节点时, 主机 VMM 会为其打开真实的 GPU 设备节点, 作为一个单独的文件描述符). 这意味着客机 GPU 进程就像原生 GPU 进程一样彼此隔离.
截至今天, DRM 原生上下文仅为 freedreno 上游化, 因此如果您习惯于 x86 机器, 您可能从未听说过它!然而, 针对 Intel 和 AMD GPU 的 PR 正在进行中, 我认为这确实是 Linux 主机上 Linux 客户机的 GPU 虚拟化的未来(也许有一天, Windows 客户机在 Windows 上运行 Mesa)!
我们在十月份的游戏更新中发布了 DRM 原生上下文, 结果不言而喻.
那么问题出在哪里呢?正如你可能预料到的, 性能并不是够原生. 性能影响来自于同步: 向 GPU 发送命令需要花费更多时间, 等待 GPU 命令完成也需要更多时间. 那些一次性“发射并丢弃”大量 GPU 工作的应用程序将会看到几乎原生的性能, 而那些经常等待 GPU 工作完成的应用程序则会遭受更高的延迟和更低的吞吐量. 使用多个 GPU 队列并在它们之间进行同步的应用程序今天也会受到影响, 因为这种同步是通过虚拟机客户机进行的, 但我们计划通过将 GPU 到 GPU 的同步移到主机内核来改善这一点, 就像原生应用程序一样(我们只是还没有实现这一点).
但刚好让 GPU 渲染在客户机中工作仅仅只是故事的一半……
窗口系统攻击
虽然 DRM 原生上下文本身允许客户机在 GPU 上渲染, 但我们还没有谈论展示的问题!也许可以使用虚拟屏幕设备, 就像传统的虚拟机一样, 让客户机在一个窗口中展示为一个独立的桌面, 但这不是我们对我们技术栈的期望. 我们希望虚拟机是一个薄层, 应用程序能够在主机窗口系统中原生地展示.
Crosvm, ChromeOS 的虚拟机监控器(VMM), 与 muvm 和 libkrun 的图形支持共享代码, 使用一种称为跨域上下文的功能来实现这一点. virtio-gpu 允许客户机打开一个通信通道, 主机 VMM 随后可以将其转发到主机合成器. Crosvm 利用这一点实现了 Wayland 转发, 使用了名为 sommelier 的客户机 Wayland 合成器. sommelier 在客户机的 Wayland 套接字上监听, 并将请求转发到主机 Wayland 合成器. 仅转发协议是不够的(否则你可以使用 virtio vsock 或 TCP 或其他任何东西来做到这一点): sommelier 还需要提取作为 Wayland 命令流一部分传递的缓冲区文件描述符, 并使用 virtio-gpu 机制在主机和客机之间直接共享它们. 这允许窗口帧缓冲区被共享, 因此它们可以在主机上合成, 而无需额外的复制成本. 在主机 VMM 一侧, 这由 rutabaga_gfx 的跨域组件处理, 该组件实现了转发 Wayland 协议的命令, 并将共享缓冲区转换回主机 Wayland 合成器可以理解的文件描述符(fds).
有一个额外的难点: 同步. 当客机上的 GPU 应用程序渲染到缓冲区时, 它会在等待渲染完成之前直接将其传递给主机. 一个称为隐式同步的机制应该让内核直接处理同步: 内核知道缓冲区上待处理的 GPU 操作, 并使 GPU 等待这些操作完成后再在另一个上下文中读取它. 隐式同步被视为一个遗留特性, 因此我们的 GPU 内核驱动程序并未实现它, 而是我们在 Mesa 中实现了它以保持兼容性(Nvidia 拒绝这样做, 这就是为什么 Wayland 在 Nvidia GPU 上长时间无法正常工作的原因……). 我们的 Mesa 驱动程序在共享缓冲区作为渲染目标时会自动插入隐式同步信息(GPU 栅栏), 并在从缓冲区读取之前在另一侧提取栅栏. 这在主机和客机上都运行良好, 但在主机和客机之间共享的缓冲区上则无法正常工作: 当客机 Mesa 在客机缓冲区中插入栅栏时, 该栅栏仅在客机内核中注册, 因此主机内核对正在进行的渲染一无所知, 无法在需要时将栅栏交还给主机 Mesa. 这导致了撕裂、视觉故障和“帧延迟”. 为了解决这个问题, 我最终还是回到了隐式同步: Asahi virtgpu 协议现在包括一个缓冲区列表, 提交方式与“经典”隐式同步驱动程序相同, 这些缓冲区在主机 VMM 中注册了栅栏, 在 virglrenderer 代码中. 隐式同步兼容性代码运行两次, 一次在客机 Mesa 中, 一次在主机 VMM 中, 以覆盖所有基础需求. 未来, 我们确实计划正确实现显式同步, 将其与跨域内容集成, 并移除这个临时解决方案, 但这需要等一段时间, 因为它需要未上游的客机内核补丁……不过我扯远了.
X11 怎么样?大多数游戏需要 X11 才能运行, 因此 sommelier 可以在客户机中运行自己的 XWayland 实例以提供 X11 支持. 简单吧?
我们在十月份发布了这个解决方案, 但……效果并不好.
Sommelier 的苦恼
事实证明, sommelier 并不是我们所希望的那样理想的解决方案. 它是为 ChromeOS 主机设计的, 在更通用的 Linux 桌面上效果并不好.
sommelier 既做得太多又做得太少. 这是一段相当复杂的代码, 进行大量的 Wayland 协议解析、缓冲区复制等. 这意味着在客机上的应用程序并不像在主机上原生运行的应用程序那样表现. 像 DPI 缩放和窗口/弹出窗口位置等问题很多. 同时, sommelier 在与 XWayland 的集成方面做得不够. 在 KDE Plasma 等流行的 Wayland 桌面环境中, 合成器做了很多额外的工作, 以正确地与 X11 应用程序集成, 直接与 XWayland 对话以管理它们. 所有这些在 sommelier 中都无法实现, 它仅提供基本的 X11 集成. X11 应用程序缺少标题栏, 菜单无法正常工作, 剪贴板无法正常工作, 没有系统托盘集成, 一些窗口显示得奇怪透明……
此外, sommelier 是用 C 编写的, 并没有完全隔离客户端连接. 它通常与 XWayland 客户端配合得不错, 但一些奇怪的情况可能导致它崩溃并使整个虚拟机环境瘫痪. 原生 Wayland 代理是不可行的: 我们尝试过, 但它太不稳定, 根本无法使用.
因此, 我们决定将 sommelier 和 XWayland 作为仅支持 X11 的解决方案(不支持 Wayland 套接字)进行发布, 并将其宣传为仅限游戏的解决方案, 因为全屏应用通常运行得足够好. 这意味着在大画面模式下运行 Steam(因为窗口模式相当不稳定). 这也意味着使用窗口启动器的游戏通常无法使用.
但我们需要一个更好的解决方案.
X11 优先?
在 muvm 甚至还没有被称为 muvm 之前, 我曾尝试过通过 virtio vsock 套接字进行直接的 X11 转发. 这的工作方式与通过网络或 SSH 隧道运行 X11 非常相似. 这样做的缺点是它无法与 GPU 加速一起工作, 因为没有办法通过这样的“愚蠢”套接字传递 GPU 缓冲区. 尽管如此, 在强制软件渲染的情况下运行一些应用程序时, 很明显这对于非游戏应用程序来说是一个更好的解决方案. X11 应用程序的工作方式与在主机上完全相同, 没有窗口管理问题, 剪贴板和托盘集成正常工作等. 我准备将其作为非游戏应用程序的替代方案直接发布, 但我想知道实现 GPU 加速会有多困难……然后 chaos_princess 出现了, 带来了他们称之为 x112virtgpu 的东西.
为什么要关注 X11, 明明 Wayland 才是未来?很简单, 因为大多数人想运行的 x86/x86-64 应用程序并不是为 Wayland 支持而构建的, 或者是在 Wayland 支持之前就存在的. 虽然我们在 Asahi Linux 上对本地桌面环境全力支持 Wayland, 但 XWayland 仍然得到全面支持, 对于在仿真下运行的游戏和遗留应用程序, 优先考虑 X11 协议支持是明智之举. 我们在十月份发布的解决方案尽管在底层使用了 Wayland, 但从未支持 Wayland 应用程序(我们尝试启用它, 但确实存在严重问题), 因此目前切换到仅支持 X11 的解决方案并不是一种退步.
x112virtgpu, 现在更名为 muvm-x11bridge, 正是我们希望 sommelier 成为的样子: 一个用于 X11 协议的轻量级代理, 它使用跨域通道直接转发到主机 X 服务器, 同时通过帧缓冲区而无需任何复制, 使用 virtgpu 缓冲区共享. 与 sommelier 不同, 它并不试图对 X11 协议进行过多解释, 只提取需要特殊处理的命令. 这意味着它的工作效果与直接的 X11 直通一样好, 并且具备 GPU 加速和缓冲区共享.
…这只是理论上. 有那么一个小小的陷阱…
锁住啥?
X11 协议非常独特. 除了通过文件描述符传递帧缓冲区外, 它还传递其他东西: 栅栏. 不, 不是现代 GPU 显式同步栅栏(这些在最近的 X11 中也得到了支持, 但那是另一个故事). CPU 侧栅栏是通过… 锁实现的.
啥?
Futex 是一个内核系统调用, 用于在 Linux 上进行跨线程和跨进程的同步. 它基本上是一个自定义互斥量原语. 两个线程或进程应该直接共享内存, 并使用原子操作进行同步. 当一个进程需要等待另一个进程时, 它使用内核 futex() 系统调用将自己置于睡眠状态, 而当另一个进程需要唤醒它时, 它使用相同的系统调用来实现. 内核确保系统调用与共享内存的实际值同步, 因此不存在竞争条件.
我们需要在主机和客机进程之间实现这一点……但没有跨域的 futex() 系统调用. 主机和客机内核对彼此的锁一无所知. 为了使这一切能够工作, 我们需要共享内存……
我们可以在高层次上解决这个问题, 解释 X11 协议以更好地理解 futex 栅栏的确切用途. 每一方, 主机 VMM 和 x11bridge, 都必须理解哪一方负责发出信号和等待 futex. 然后, 信号端的代理组件必须等待信号, 然后发送跨域命令将该信号转发到另一端. 这是可行的, 但这将需要大量工作, 并增加额外的延迟: 如果一方不在等待另一方, futex 机制应该完全不需要任何系统调用, 而是直接使用原子操作.
所以 chaos_princess 决定尝试其他方法: 如果我们真的可以共享内存呢?如果主机和客户进程能够一起映射一个共享内存缓冲区, 那么它们就可以像在同一侧运行一样使用原子操作, 然后我们只需以某种方式代理 futex() 系统调用的使用. 这被证明是可行的, 但我们如何共享内存呢?我们可以使用 GPU 缓冲区, 但这似乎有点过于复杂, 并且实际上无法直接与 X 服务器和客户端集成……
负责处理 X11 共享内存栅栏的库是 libxshmfence. 该库可以使用多种机制来共享内存. 在 Linux 上, 它默认使用 memfd() , 这是一个创建“内存中”文件的系统调用. 我们可以跨虚拟机边界共享这些吗?不幸的是, 不能轻易做到.
但还有另一种方法.
在 muvm 中, 我们已经将主机文件系统直接共享给客户机. 这本质上是一个通过 FUSE 文件系统代理到虚拟机的文件系统. 通常, 这在读取和写入文件时通过复制数据来实现. 然而, 有一种特殊模式, 称为 virtiofs DAX, 它允许客户机直接将主机文件映射到内存中!当一个文件系统以 DAX 共享并挂载时, 主机和客户机中同一个文件的 mmap() 实际上会直接共享内存, 并且原子操作将在客户机和主机之间工作!这有多酷啊?
事实证明, DAX 有点新且略有问题, 我最终不得不向 libkrun 和客机内核发送几个补丁, 以使其可靠地工作(我们仍在弄清楚如何将其中一些补丁上游化……). 但一旦它工作了, 这意味着我们可以在客机和主机之间直接共享内存. muvm 现在通过在客机中挂载 /dev/shm 并支持 DAX 来实现这一点, 因此主机和客机可以分享 POSIX 共享内存.
但是……libxshmfence 仍然坚持使用 memfds. 我们该如何解决这个问题?
chaos_princess, 忠于他们的名字, 决定用他们的解决方案全力以赴地进入混乱模式: ptrace! 当 muvm-x11bridge 从客户端进程获取 memfd 时, 它会进行 ptrace 并注入必要的系统调用以打开 /dev/shm 文件, 并像什么都没发生一样交换文件描述符. 然后, 文件名可以直接传递给主机, 在那里 libkrun 可以打开它并将 fd 交给 X 服务器, 假装无事发生.
然后, muvm-x11bridge 运行一个小的 futex 监视线程, 该线程检测来自客户端进程的 futex() 唤醒调用, 并将唤醒发送到主机, 主机可以将其转发到 X 服务器.
疯狂!但它有效……某种程度上?调试整个设置花了相当长的时间, 因为 ptrace() 之舞非常挑剔, 经过几次尝试才使其正常工作, 而 futex() 代理也证明很难做到正确. 最终我们确实让它相当可靠地工作, 但有一个显著的限制: 你不能在 X11 客户端应用程序中将 ptrace 用于其他目的, 因为这会破坏 muvm-x11bridge . 这意味着你不能使用 strace 来调试某些事情, 而一些喜欢使用 ptrace 的复杂应用程序(如 Chromium 和基于 Chromium 的应用程序)会遇到麻烦.
一个可能的替代方案是使用 LD_PRELOAD 来劫持 libxshmfence, 这也是 chaos_princess 实现的另一个解决方案……但由于我们还要在 3 个架构(本地 arm64、模拟 x86 和模拟 x86-64)之间进行这一切, 我们必须提供三个版本的库, 并且这个解决方案也不能保证与容器技术正常工作.
如果我们真的想要发布这个, 我们需要一个更好的解决方案……
锁住第二版
仔细查看 libxshmfence 代码, 会发现如果 memfd() 不起作用, 还有几条后备路径. 首先, 它使用 shm_open(SHM_ANON, ...) , 但那是 BSD 的东西, 在 Linux 上不可用. 然后, 它尝试 open() 与 O_TMPFILE , 但 O_TMPFILE 不被 virtiofs 支持. 最后, 它以老派的方式操作, 通过在 /dev/shm 中打开一个文件并取消链接. 如果我们能让它不使用 memfd() , 它就会完全按照我们的想法执行. 我们能做到吗?
我尝试了几种方法, 包括使用 seccomp-bpf 过滤器来禁用 memfd() 系统调用. 不幸的是, 这会破坏一些代码路径, 例如 FEX 中的一些代码路径, 这些路径假设 memfd() 存在并且正常工作(在任何现代 Linux 内核上, 这都是一个相当合理的假设).
所以…我最终只是向 libxshmfence 发送了一个小的合并请求, 以允许通过环境变量禁用 memfd() 的使用…并且它被合并了!
此补丁尚未作为新版本的 libxshmfence 发布, 因此任何希望发布新 muvm 版本的发行版目前都必须将此补丁回移植到其 libxshmfence 软件包中, 以避免依赖不太可靠的 ptrace() 黑客手段.
幸运的是, 这些栅栏总是在 X11 客户端上创建并共享给 X 服务器, 因此只有客机中的 X11 客户端需要这些黑客手段, 而 X 服务器可以使用 libxshmfence, 而无需任何额外的环境变量或补丁.
我们做到了, 对吧?还不够…… libxshmfence 仍然删除共享内存文件, 并仅将 fd 传递给 X11 服务器. 这是可取的(它避免在错误情况下留下过时的文件), 我们不想在 libxshmfence 中引入更多的黑客手法……那么如果我们无法重新打开文件, 如何将 fd 传递给主机端呢?
好吧……如果你想想, 即使文件被删除, 客体中打开的每个文件描述符实际上都是由主机虚拟机监控器打开的. 这就是 virtiofs 的工作原理!所以主机已经在某个地方拥有我们需要的文件描述符……我们只需要找到它. 为了使这项工作得以实现, 我最终在 libkrun 中的 virtiofs 实现中添加了一个奇妙的文件描述符导出 ioctl() . 这有点像导出 GPU 缓冲区, 并给你一个可以作为 X11 跨域协议的一部分传递给主机的标识符, 然后可以引用一个特殊的导出文件描述符表来定位底层主机 fd. 这是通过在 virtiofs 代码和 rutabaga_gfx 跨域代码之间共享导出 fd 表来实现的, 这需要经过相当多的代码层……但 Sergio 对这个解决方案很满意, 并合并了我的 PR ^^.
这个技巧并不安全, 因为多个独立的跨域客户端(可能以不同用户身份运行)可能会窃取彼此的文件描述符, 但我们总是只有一个 muvm-x11bridge 实例, 并且整个微虚拟机在单个用户的权限上下文中运行, 因此这不会影响我们的用例. 此外, 我认为今天 virtgpu 跨域没有任何有意义的权限检查.
最后, 在对 futex 和跨域 X11 代码进行了更多调试后, 它终于稳定并准备好合并和发布了!
Wayland 怎么办?
在未来, 我们还希望支持原生的 Wayland 直通. 为此, 我们需要一个与 muvm-x11bridge 相对应的 Wayland 组件. 与 sommelier 不同, 这个计划将简单得多, 并遵循相同的理念, 我们预计它的工作效果将与 X11 直通一样好. 然而, 我们可能应该先解决栅栏和显式同步的问题, 因此纯 Wayland 直通将暂时留在待办事项列表上. 好消息是它没有任何奇怪的 futex 问题!
重新载入 Muvm
如果你从今天开始使用 sudo dnf update --refresh 更新你的 Fedora Asahi Remix 系统, 你将获得自十月发布以来我们 x86 模拟栈的所有这些改进:
Muvm 变更
muvm-x11bridge用于 X11 直通(你可以使用--sommelier恢复到 sommelier, 但为什么要这样做呢?).- Steam 和其他窗口应用程序现在正常工作, 甚至系统托盘图标也能正常使用.
- 如果在主机上正确配置了它们, 你还可以在 Steam 中使用老旧的 XIM 输入法进行 CJK 输入!(在 KDE Plasma 上测试过 fcitx. )
muvm-hidpipe现在已集成, 因此游戏手柄将无需使用我们的 steam 包装器即可工作. 实际上, 在安装 Steam 一次后, 你可以使用muvm -- FEXBash -c '~/.local/share/Steam/steam.sh'运行它, 而不会丧失任何功能./dev/shm现在在主机和客机之间共享, 启用了有趣的用法.- 客机内存现在得到了更好的管理, 这应该会导致更少的主机 OOM.
- 8GB 机器默认分配更高的内存, 这使得更多游戏可以在这些机器上运行.
- 在已经运行的虚拟机中以交互模式运行命令. 例如, 运行
muvm -ti -- bash以获取一个 shell. - 你还可以通过连接到根服务器端口:
muvm -tip 3335 -- bash以 root 身份运行命令. - 许多小改进和修复.
FEX 变更
- 许多错误修复和改进, 包括针对新的 Steam CEF 更新的修复.
virglrenderer 和 Mesa 变更
- Vulkan 1.4 支持
- 许多错误修复和性能改进
Steam 包装变更
- Steam 现在以常规窗口模式启动, 而不是大屏幕模式.
我们还自动化了安装运行非 Steam 应用所需的所有组件, 因此如果你不想运行 Steam, 则不需要我们的 steam 软件包. 只需按照上述步骤先更新你的系统, 然后 sudo dnf install fex-emu 以获取运行 x86 和 x86-64 应用所需的一切与 muvm .
现在窗口管理工作得相当不错, 我们鼓励你尝试非游戏应用程序. 一般来说, 作为独立 tarball 打包的应用程序(没有复杂的操作系统依赖或与其他应用程序的交互)可能会运行良好, 包括 AppImages. 请注意, Flatpak 目前不与 FEX/muvm 集成, 因此 x86-64 Flatpak 还无法使用. 请告诉我们它对你来说运行得如何!