大家好,我是朝日丽奈!✨
你们可能已经知道了,我和 Asahi Linux 团队的其他成员一起为 Apple Silicon 平台开发开源 GPU 驱动程序。这真是一段惊险刺激的旅程!去年底我们发布了第一个版本的驱动程序,在多个月的逆向工程和开发后终于完成。但那只是开始……
今天我们为 Asahi Linux 发布了一个重大更新,所以我想跟大家谈谈自那时以来我们都在做些什么,并展望未来!
如果这是你第一次听说我们的 GPU 冒险,请先查看我的[[关于 M1 GPU 的故事|tales-of-the-m1-gpu]]文章,它涵盖了我去年所做的内容!还有不要错过 Alyssa 在她网站上撰写的精彩系列文章,从2021年1月开始追溯到现在!^^
如果太长了,请随意跳到结尾部分,了解这对 Asahi Linux 意味着什么!
什么是 UAPI ?

在每个现代操作系统中,GPU 驱动程序被分为两部分:用户空间部分和内核部分。内核部分负责管理 GPU 资源以及它们在应用程序之间的共享方式,而用户空间部分则负责将来自图形 API(如 OpenGL 或 Vulkan )的命令转换为GPU需要执行的硬件命令。
在这两个部分之间,有一个称为 UAPI 的东西。这是它们之间通信所使用的接口,并且对于每种类别的 GPU 都是特定的!由于用户空间和内核之间确切的拆分取决于每个 GPU 设计如何,并且由于不同的 GPU 设计需要传递不同位数据和参数以在用户空间和内核之间进行传递,因此每个新 GPU 驱动程序都需要其自己独特的 UAPI。
在 macOS 上,由于苹果控制着内核驱动程序和用户空间 Metal / GL 驱动程序,并且作为新 macOS 版本一 部 分始终更新,在他们想要时可以更改 UAPI 。因此 ,如果他们需要支持新型号显卡,则无需担心 。或者他们需要修复错误或设计缺陷 , 或者进行更改以提高性能 , 这并不成问题!他们无需过多担心正确获取 UAPI , 因为随后可以随时更改它。但是,在 Linux 上情况并非如此简单…
Linux 内核具有超级严格的用户空间 API稳定性保证 。这意味着较新版本的 Linux 内 核必须支持与旧版相同的 API,并且旧应用程序和库必须继续与较新版本兼容 。由于图形 UAPI 可能相当复杂,并经常需要随着任何给定驱动器添加新 GPU 支持而发生变化,因此具有良好 UAPI 设计非常重要!毕竟,一旦驱动器进入上游 Linux 内核 ,你就不能破坏与旧 UAPI 的兼容 性了。如果出错了,则会永远困扰你。这使得 UAPI 设计成为一个非常困难的问题!甚至 Linux DRM 子系统也针对 GPU UAPI 制定了特殊规则以尝试最小化这些问题…
UAPI 蹒跚学步
当我开始研究驱动程序时,我的第一个目标是弄清楚 GPU 及其固件的工作原理以及如何与它们通信(图中的固件 API )。首先,我用 Python 编写了一个演示程序,可以通过 USB 远程运行并渲染单个帧。然后我意识到我想直接将 Alyssa 的 Mesa 驱动连接到它上面,这样我就可以运行真正的演示和测试应用程序。 Mesa 已经有一个名为 drm-shim 的测试工具,可以伪造 Linux DRM UAPIs ,所以我只需要将 Python 解释器嵌入其中!但我们还没有自己的驱动 UAPI …
因此,我复制粘贴了 Panfrost UAPI ,并对其进行了简化!由于 drm-shim 不是真正的 Linux 内核,并且由于我的 Python 驱动程序只是在单个进程中运行的演示版本,在提交命令给 GPU 时无法实现并发:当应用程序向 GPU 提交命令时,Python 驱动程序会立即执行它,并且在一切完成之前不会返回给应用程序。那时候这完全没有关系,因为通过 USB 连接运行所有内容才是更大的瓶颈!
随着我逆向工程更多关于 GPU 方面的东西, 我找出如何正确地做并发处理, 并且有几个基于 Python 的演示可同时在 GPU 上运行多项任务. 因此, 当编写 Rust 中真正 Linux 驱动時, 我大部分都知道需要设计哪些功能! Rust 驱动程序核心支持同时运行多项任务, 事实上,在12月份发布后你可以同时运行使用 GPU 的多个应用程序,并且他们(原则上)可以并发地向 GPU 提交工作而互相不阻塞。但… 在那个时间点上… 我已经把 demo UAPI 连接到 Mesa 上了!
那么该 UAPI 存在什么问题?就像 Python 演示一样 ,整个 GPU 渲染过程都是同步进行: 当应用提交任务给 GPU 时 , 它将被排队等待固件执行 , 只有当所有操作完成后才会返回调用结果 。这意味着 CPU 和 GPU 不能在单个应用内同时处理任何内容!而且回去 CPU 和 GPU 之间存在一定延迟 , 进一步降低性能 …

值得庆幸的是,GPU 和 CPU 都非常快,即使出现了这种糟糕的设计,一切仍然足够快到可以在 60FPS 下提供可用的桌面体验。🚀
但显然这样做不行,考虑到推往上游这更是一种糟糕的设计,因此我们必须想出更好的解决方案。
GPU 同步
一旦你开始并行运行东西,就会遇到如何保持所有事情同步的问题。毕竟,在 CPU 提交工作给 GPU 后,它可能实际上必须在某些时候等待 GPU 完成才能得到可使用的结果。不仅如此,提交给 GPU 的不同工作片段通常彼此依赖!这些依赖甚至可以跨应用程序延伸:游戏可以排队多个渲染通道以复杂方式相互依赖,然后最终场景必须传递给 Wayland 合成器,在场景完成渲染之后才能开始合成。更重要的是,Wayland 合成器必须在显式控制器上排队翻页以显式新帧,但只有当帧完成渲染时才能发生这种情况!

所有这些事情必须按正确的顺序发生,才能使一切正常工作,并且 UAPI 必须提供机制来实现它。随着图形 API 多年来的变化,这种方式也在改变。通常来说,UAPI 基于 OpenGL 的“隐式同步”模型…
隐式同步
隐式同步模型基于这样一个想法:同步与缓冲区密切相关,缓冲区是指像纹理和帧缓冲之类的东西。当工作被提交到 GPU 时,内核驱动程序追踪它从哪些缓冲区读取数据以及向哪些缓冲区写入数据。如果正在读取或写入任何已经(或将要)被先前提交的 GPU 工作所写入的缓冲区,则驱动程序确保在那些任务完成之前不会开始执行。在内部,这通过每个缓冲区包含一个或多个 DMA 栅格来实现,该栅格追踪读取方和写入方,并允许读取方阻塞先前的写入方。
这很有效!这意味着应用程序开发人员不必太关心同步问题:他们只需渲染到纹理中,然后稍后使用它即可,而驱动程序通过追踪依赖项使一切看起来像是按顺序执行。这也适用于应用程序间甚至 GPU 和显式控制器之间。
不幸的是,这个模型的效率并不高。这意味着内核需要追踪所有可能使用所有渲染作业的 GPU 缓存!假设游戏使用100种纹理:那么每次渲染场景时都必须检查确保没有人正在对其进行写入操作,并标记为正在被读取。但怎么会有人对它们进行写入操作呢?毕竟,大多数纹理通常只加载到内存中一次并且永远不再接触了。但是内核并不知道这件事…
如今所有 Linux 主线 GPU 驱动都支持此模型!尽管一些驱动程序已经添加了显式同步支持(例如 amdgpu ),但它们仍然具有完全隐式同步支持底层功能。还记得 UAPI 稳定性规则吗…?
显式同步
接着 Vulkan 出现了,并表示存在更好的方法。在 Vulkan 中,缓冲区没有隐式同步。相反,应用程序开发人员负责手动追踪提交到 GPU 的事物之间的依赖关系,并且 Vulkan 提供了几个工具来告诉系统它需要什么:屏障、事件、栅格和时间线信号量。
Vulkan 相当复杂,所以我们不会详细介绍……但基本上,这些工具使应用程序对等待什么和何时等待拥有精细控制。不再存在隐式缓冲区同步,这很棒!内核驱动程序不再需要追踪可能有数十个或数百个缓冲区,而只需满足应用请求的非常特定的同步要求。
(顺带一提,Metal 由于某种原因支持显式同步和隐式同步,但这偏离主题了……)
在底层中,Linux 使用称为 同步对象 的标准机制实现显式同步。每个 sync object 基本上是一个完形容器,实际上是 DMA 栅格。如果你曾经使用过异步编程框架,则可能听说过 promises。DMA 栅格基本上是 GPU 版本的 promise !同步对象实际上最初是 OpenGL 的概念,后来被改编并扩展以适应 Vulkan 更复杂的要求。
在显式同步世界中,在将 GPU 工作提交给内核时,它会提供输入 同步对象 列表和输出 同步对象 列表。内核驱动程序检查所有输入 同步对象 并注册其栅格作为 GPU 工作的依赖项。然后创建新(挂起的)完形栅格以进行工作,并将其插入输出 同步对象 中(请记住, 同步对象是栅格的容器, 因此可以替换)。然后驱动程序将工作排队执行,并立即返回用户空间. 然后,在后台, 只有当所有依赖的栅格被信号触发时才允许执行该任务, 接着当任务完成时触发自己的完形栅格。哇!一个漂亮、干净、现代化的内核 UAPI 同步方式!
除了一个问题…
窗口系统的麻烦
在单个应用程序中,Vulkan 让你得以处理好同步问题。但是跨应用的同步又该如何进行呢?比如当游戏向 Wayland 组合器发送帧?这可以使用 同步对象 … 但是在 Linux 同步对象 被发明之前,Wayland 已经有将近 10 年的历史了!
当然,在桌面 Linux 中的所有现有窗口系统集成标准都假定成隐式同步。我们当然可以向它们添加显式同步,但那会破坏向后兼容性…
所有现有的 Linux 驱动程序所做的就是… 两者都支持。你仍然需要给内核驱动程序一个读/写缓冲区列表,并且可以排除掉例如驱动程序知道的不与任何其他进程共享的纹理之类的东西。然后内核会隐式地与这些缓冲区进行同步,并显式地与 同步对象 进行同步。这样做可行,但又使得驱动程序变得更复杂了…
我们需要一种方法来在隐式和显式同步世界之间建立桥梁,而无需为每个驱动重新发明轮子。值得庆幸的是,Linux DRM 子系统开发人员一直在努力解决此问题,并且几个月前我们终于找到了解决方案!
桥接两边的世界
记得我说过,隐式同步是通过将 DMA 栅格附加到缓冲区来实现的,而显式同步则是通过在 同步对象中使用 DMA 栅格来实现的吗?
就在去年 2022 年 10 月发布了 Linux 6.0 版本之前几个月,我们发布了 Asahi 驱动程序。随着它的推出,带来了两个新的通用 DRM API:一个用于将 DMA 栅格导入到 DMA-BUF 中,另一个用于从其中导出。
结合现有的通用 同步对象 API,这让我们完全弥补了天堑!用户空间应用程序现在可以从 DMA-BUF(与另一个进程共享的缓冲区)中取出栅格,并将其转换为 GPU 工作等待的 同步对象,然后获取该工作输出 同步对象,并将其栅格插入另一个可与其他进程共享的 DMA-BUF 中。
如果你想要更多细节,请参阅 Faith Ekstrand 写的一篇优秀文章!她也是一位非常好的导师,没有她帮助我无法理解所有这些 UAPI 设计方面内容。
太棒了!这解决了我们所有问题!但正如人们所说,“魔鬼藏在细节中”…
OpenGL 有话对你说…
显式同步很棒,但我们还没有 Vulkan 驱动程序,我们只有 OpenGL 驱动程序。我们该如何完成这项工作?
OpenGL 过度基于隐式同步模型。因此,为了使 OpenGL 驱动程序与显式同步 UAPI 配合工作,驱动程序必须负责在两个世界之间搭建桥梁。当然,我们可以回到每个单独缓冲区上导入/导出屏障的方式,但这比一开始就在内核中进行隐式同步更慢…
还有一个更大的问题:即使忽略缓冲区同步问题,在隐式同步世界中,内核会追踪 GPU 所需的所有缓冲区。但在显式同步世界中不会发生!这意味着应用程序可能使用纹理进行渲染,然后释放和销毁纹理…而在显式同步驱动程序中,则意味着立即取消分配该纹理,即使 GPU 仍在使用它! 在 Vulkan 中这将是一个应用错误, 但是在 OpenGL 中必须正常工作…
Mesa 中的显式同步主要用于 Vulkan 驱动器, 但由于原始显式同步 Linux GPU 驱动程序 尚未存在于主线, 因此 Mesa 中没有 OpenGL(Gallium)驱动程序可以实现 这一点!他们大多数只使用遗留的隐式同步路径… 所以我没有可以参考的代码,不得不自己找出如何让它全部运行 ^^;;
因此我开始寻找方法来使 Alyssa 和我正在开发的 Mesa 驱动程序能够使显式同步工作。幸好,它不需要太多重构!
如你所见,为了在基于区块格的移动 GPU 上获得良好的性能,你不能直接将 OpenGL 映射到硬件。在基于区块格的 GPU 上,东西不会立即被渲染到帧缓冲区中。相反,首先收集一整个几何场景,然后通过顶点着色器运行它,并根据屏幕位置将其分成块,并最终在超快速的块内存中逐个块地呈现出来,然后写入帧缓冲区。如果你将渲染拆分为许多小步骤,则意味着每次加载和保存帧缓冲区在这些 GPU 上都非常慢!但是 OpenGL 允许应用程序随时切换帧缓冲区,并且许多应用程序和游戏经常这样做…如果我们每次发生这种情况时都刷新渲染,真的会非常慢!
因此,Alyssa 为 Panfrost 驱动程序开发了一个批处理追踪系统(基于 Rob Clark 原本为 Freedreno 的实现),并稍后向 Asahi 驱动程序添加了类似的系统。这个主意是不要立即发送工作到 GPU 中,而是将其收集到批处理中。如果应用程序切换到另一个帧缓冲区,则保留批处理不变,并创建新批处理。如果应用程序再次切换回原始帧缓冲区,则只需再次切换批处理并继续附加工作以进行原始批处理。然后,在实际需要呈现所有内容时,你可以将完整的批量提交给硬件。
当然,在这里有一个问题…如果应用程序试图从之前呈现过的帧缓冲读取数据怎么办? 如果我们还没有提交该批次,则会获取错误数据…因此,批处理追踪系统为每个缓冲器追踪读取方和写入方, 并且任何时候当前批次需要输出它们时就会把批次提交给 GPU。
等等……那听起来不就又开始隐式同步了吗?
最后驱动已经具备我所需要核心部分!批处理追踪可以:
同时追踪多个彼此独立但相关联 GPU 工作
根据读/写 buffer 追踪它们之间依赖关系
保持他们需要使用的 buffer 在批次提交至 GPU 之前存活
我只需要扩展批处理追踪系统,在除了仅追踪未提交的 GPU 工作以外,还要追踪已提交到内核但尚未完成的工作!然后现有的读写器机制可用于确定哪些缓冲区被读取和写入。由于批次在单个队列中提交到 GPU 并按顺序执行,因此我们大多数情况下无需担心在批次之间进行同步,只要在每个批次之前添加完整的 GPU 屏障即可。
这最终成为一个中等大小但不太笨重的提交。大部分更改都是在批处理追踪代码中进行的,并且主要是将现有代码扩展以处理非活动但已提交的批次的想法。然后我们使用现有的 Linux 同步对象 API来确定何时实际完成了批处理,然后最终清理掉这些批处理。通过这样做,显式同步就起作用了!
嗯… 某种程度上吧。它适用于无界面(离屏)渲染测试,但我们仍然需要解决如何处理与其他应用程序共享缓冲区的难题…
隐式同步的许多尖锐边角问题…
实际上存在着一个我可以参考的驱动程序。尽管它尚未合并,但英特尔新的 Xe 内核驱动程序也是全新的、纯显式同步驱动程序,Mesa 方面将其支持添加到现有的 Intel Iris Mesa 驱动程序中。事实上,Asahi 驱动程序的 UAPI (在 Faith 建议下)受到了 Xe 的很大启发!
这两个 GPU 工作方式以及驱动程序设计方式过于不同,无法使用 Xe/Iris 作为如何使内部批处理追踪与显式同步在驱动程序中工作的示范,但我们至少可以看一下它如何处理共享缓冲区隐式同步。这个想法证明非常简单:
在提交工作给 GPU 之前,查找所有使用过的缓冲区,并找出任何一个共享的缓冲区,然后获取它们的 DMA 栅格并将其设置为输入同步对象。
提交工作后,取出输出同步对象、提取其栅格,并再次安装到所有共享缓冲区中。
走你!隐式同步窗口系统集成得到了支持!
然而 Firefox 开始在 WebGL 测试中崩溃了…
薛定谔的缓冲共享
作为新 UAPI 设计的一部分,驱动程序应该告诉内核何时可以共享缓冲区。内核仍然需要知道应用程序已分配的所有缓冲区,并且由于内存管理中的边角情况(尽管在我们的驱动程序中尚未实现,但将会存在),当你使用 GPU 进行操作时仍然需要锁定它们。因此,在像 i915 这样的现有驱动程序上,即使 GPU 没有使用全部缓冲区,内核也可能锁定数千个缓冲区!这很糟糕,因此 Xe UAPI 具有一种优化方法,我将其带到了 Asahi:如果你将一个缓冲区标记为不共享,则内核会将其与所有其他非共享缓冲区分组,并且它们共享相同的锁。这意味着你永远不能在进程之间共享那些缓冲区,并且内核会阻止此类行为。Mesa 中 Gallium 驱动层具有一个标志来指示是否可能共享缓冲区,在创建时传递。所以这很简单,对吧?
除此之外,在OpenGL中这是合法的:
glTexStorage2D(...)(创建纹理,分配存储空间,上传数据)eglCreateImageKHR(...)(将纹理转换为 EGL 图像)eglExportDMABUFImageMESA(...)(导出它)
OpenGL 驱动程序无从得知在创建纹理时你要共享纹理。它看起来好像没有被共享,然后突然就被共享了。糟糕!
事实证明,这是 Mesa 中现有的与显式同步无关的其他原因造成的问题。有一个名为 flush_resource 的 Gallium 回调函数,驱动程序应该在此使资源可共享。因此,我添加了一些代码来重新分配和复制缓冲区以使其可共享。这不是最快速度的解决方案,我们可能会在将来进行更改,但目前可以使用…
一切都完成了,对吗?
21:05 <alyssa> lina: still have magenta rectangles in supertuxkart with latest branches
21:20 <jannau> still at startup in one of two starts? was fine in the stream under plasma/wayland
21:21 <alyssa> yes
21:22 <alyssa> in sway if it matters
21:22 <alyssa> also saw it sometimes in nautilus
21:23 <alyssa> right, can't reproduce in gnome
21:23 <alyssa> but can reproduce easily in sway
21:23 <alyssa> so ... more WSI junk
21:23 <alyssa> and yeah goes away with ASAHI_MESA_DEBUG=sync
21:24 <alyssa> so... some WSI sync issue that only reproduces with sway
21:24 <alyssa> and supertuxkart is the easiest reproduce
03:20 <lina> alyssa: Only on startup and only on sway? Hmm... that's starting to sound like something that shouldn't block release at this point ^^;;
03:20 <lina> Does it go away with ASAHI_MESA_DEBUG=sync only for stk, or for all of sway?
03:26 <alyssa> lina: setting =sync for stk but not sway is enough
03:27 <alyssa> but it's not just supertuxkart that's broken, it's everything, this is just the easiest reproducer
03:27 <alyssa> so yes, this is a regression and absolutely does block release
薛定谔的缓冲共享,其之二…
长话短说,事实证明应用程序也可以这样做:
创建一个可共享的帧缓冲区,但暂不共享。
将东西渲染到缓冲区中。
进行共享。
当我们提交渲染命令,看起来它还没被共享,所以驱动并不会执行隐式同步操作…然后应用共享了,太迟了,并且没有用正确的栅格附加上。另一边的什么东西会试图开始使用这个缓冲区,并不会等到渲染完成。哎呀!
我必须添加一个机制来追踪所有已提交但未完成批次的同步对象 ID,并将其附加到所有写入的缓冲区上。然后如果在我们得知这些批次完成之前就共享了这些缓冲区,则可以回溯附加栅格。
有趣的是,当我向正在处理 Xe 合并请求的英特尔工作人员提出此问题时……他们以前从未听说过!看起来他们的驱动程序可能存在相同的错误……我想他们可能需要开始使用 Sway 进行测试了^^;;
我们可以结束了吗?大部分都结束了,虽然还有一些漏洞需要解决……但我们还没讨论到内核呢!
当显式同步遇上 Rust
Asahi DRM 内核驱动程序的前一个版本在与内核的交互方面非常简单,因为它具有非常简单的 UAPI 。我只需要为这些 DRM API 添加 Rust 抽象层:
drv和device,DRM 驱动和处理设备的核心。file,是 DRM 驱动和用户空间交互方式。gem,管理具有统一内存的 GPU 的内存。mm,一个通用的内存范围分配器,我的驱动上用它处理许多事情。ioctl,只是一个包装器,用于计算 UAPI 的 DRM ioctl 编号。
为了添加适当的显式同步支持,我需要添加一堆新的抽象!
dma_fence,Linux DMA 栅格机制的核心。syncobj, DRM 的同步对象 API 。sched,DRM 组件负责实际排列和调度 GPU 工作的部分。xarray,一个通用内核数据结构,基本上是int→void*的映射,被我用于通过其唯一 ID 追踪用户空间的 UAPI 对象,例如 VM 和队列等。
我现在已经发送了所有 DRM 抽象以等待初步审核,以便于尽可能快地把它们变成上游,之后,我们就可以把驱动本身上游化了!
作为这项工作的一部分,我甚至在 DRM 调度程序组件中发现了两个内存安全漏洞,这些漏洞导致 Alyssa 和其他开发人员遇到了各种内核问题,因此 Rust 驱动程序的工作也有益于使用此共享代码的其他内核驱动程序!同时,我仍然没有收到任何关于 Rust 代码中存在错误导致内核问题的报告~✨
还有更多的东西!
显式同步是此版本的最大变化,但还有更多!由于我们希望将UAPI尽可能接近最终版本,因此我一直在努力添加更多内容:
基于 Xe UAPI 模型的多 GPU VM(虚拟内存地址空间)和 GEM 对象绑定,以支持未来的 Vulkan 需求。
一个结果缓冲区,以便内核驱动程序可以将 GPU 作业执行结果发送回 Mesa。这包括统计数据和时间信息,但也包括命令是否成功以及详细的故障信息,因此你可以在 Mesa 中获得详细的故障解码!
计算作业支持,用于运行计算着色器。目前我们仍在 Mesa 方面进行这一工作,但应该足以通过大多数测试,并最终使用 Rusticl 添加 OpenCL 支持!
一次提交多个 GPU 作业,并直接指定它们的依赖关系,而不使用同步对象。这使得 GPU 固件能够自主执行所有操作,比每次都通过 DRM 调度程序更有效率。Gallium 驱动程序目前尚未使用此功能,但将来可能会使用,在我们即将推出的 Vulkan 驱动程序中肯定会使用!有很多细节需要注意关于如何处理所有排队相关的事情…
blit 命令的存根支持。我们还不知道这些如何工作,但至少在 UAPI 中提供一些骨架支持。
为了使所有这些在驱动端正常工作,我最终重构了 workqueue 代码并添加了一个全新的队列模块,该模块添加了使用同步对象追踪命令依赖关系和完成情况以及通过 DRM 调度器管理工作所需的基础设施。哇!
总结
这对于 Asahi Linux 引用发行版的用户意味着什么?这意味着…一切变得更快了!
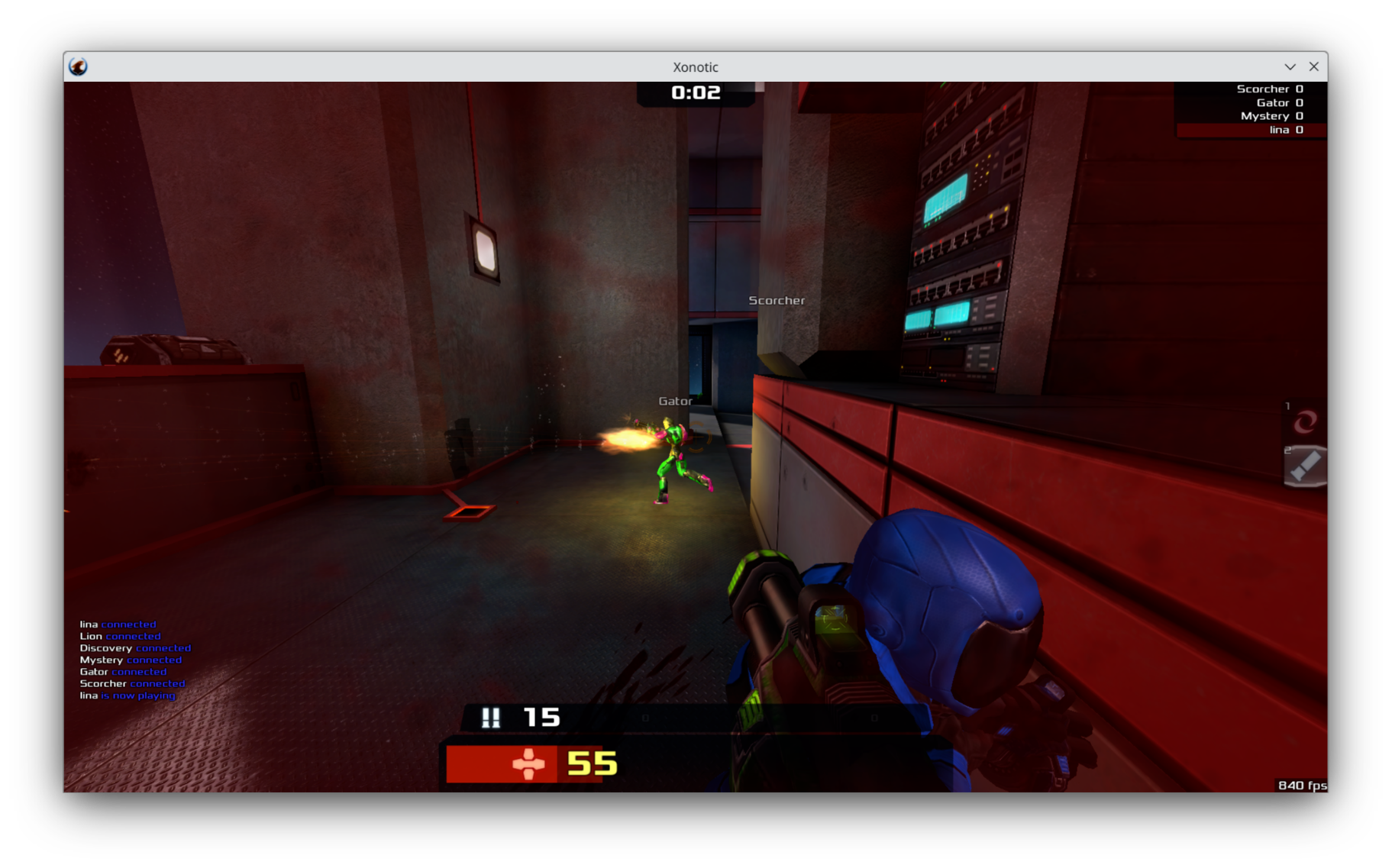
由于 Mesa 驱动程序不再串行处理 GPU 和 CPU 工作,性能得到了大幅提升。现在我们可以以超过 800 FPS 的速度运行 Xonotic,在相同硬件(M2 MacBook Air)上比 macOS 快约 600*!这证明开源逆向工程的 GPU 驱动程序确实有能力在实际场景中击败苹果的驱动程序!
不仅如此,我们的驱动程序通过了100%的 dEQP-GLES2 和 dEQP-EGL 一致性测试,这比 macOS 在该版本上具有更好的 OpenGL 一致性。但当然我们不会止步于此,由于 Alyssa 不知疲倦地努力工作,完整的 GLES 3.0 和 3.1 支持正在紧锣密鼓地进行中!你可以在 Mesa Matrix 上跟踪驱动程序功能支持进度。过去几个月已经有许多其他改进措施,并且我们希望你发现各方面都运行得更加顺畅!
当然,现在我们支持隐式同步和显式同步驱动程序后,有很多新的边角情况可以遇到。我们已经知道至少一个小型回归(当 KDE 启动时出现短暂的品红色方块),可能还有更多问题,请在 GitHub 追踪错误报告任何问题!如果能提供易于重现问题的简单方法,并且得到越来越多的问题报告,那么我们就越容易调试这些问题并解决它们^^。
请不要过于严肃地看待确切的数字,因为还有其他差异( Xonotic 在 macOS 上运行在 Rosetta 下,但由于是非 Retina 应用程序,在那里也以较低分辨率进行渲染)。重点是结果处于同一水平,并且我们将继续改进我们的驱动程序!
获得它!
如果你已经在使用 GPU 驱动程序,请更新你的系统并重新启动以获取新版本!请注意,由于 UAPI 发生了很大变化,应用程序可能会停止启动或在重启之前以软件渲染方式启动。
如果你仍然没有尝试过新的驱动程序,请安装这些包:
$ sudo pacman -Syu
$ sudo pacman -S linux-asahi-edge mesa-asahi-edge
$ sudo update-grub
然后,如果你正在使用 KDE ,请确保也安装了 Wayland 会话:
$ sudo pacman -S plasma-wayland-session
然后只需重新启动并确保在登录窗口上选择 Wayland 会话!请记住,如果你从 Xorg 切换,则可能需要在 KDE 设置中重新配置显式比例,因为 KDE 将认为你已更换了监视器。对于笔记本电脑而言,150%通常是一个不错的选择,并且不要忘记注销并重新登录以使更改完全生效!
接下来呢?
随着 UAPI 的完善和许多本地 ARM64 Linux 游戏正常运行…现在是时候看看我们可以用驱动程序运行什么了!OpenGL 3.x 支持虽然不完整,但足以运行许多游戏(如 Darwinia 和 SuperTuxKart 的高级渲染器)。但大多数游戏都不适用于 ARM64 Linux,所以…现在该看 FEX 的表现了!
FEX 在标准的 Asahi Linux 内核构建上无法工作,因为我们使用 16K 页面,但实际上添加 4K 页面支持并不是那么困难…所以从本周开始,我将向 Asahi GPU 驱动程序中添加 4K 支持,并修复沿途遇到的任何问题,然后我们将尝试在其上运行 Steam 和 Proton !让我们看看在当前状态下驱动程序可以运行多少 Steam 游戏库!我敢打赌你会感到惊讶…(还记得 Portal 2 吗?它只需要 OpenGL 2.1。由于今天我们的驱动程序已经支持 3.x,我敢打赌我们会玩得很开心~✨)
如果您有兴趣关注我的工作,可以在@[email protected]上关注我或订阅我的 YouTube 频道! 我会在每周三和周五直播 Asahi GPU 驱动程序的工作,如果您感兴趣,请随时来参加我的直播!
如果您想支持我的工作,可以在 GitHub 赞助或 Patreon 上捐赠 marcan 的 Asahi Linux 支持基金,这也会帮助到我!如果您期待 Vulkan 驱动程序,请查看 Ella 的 GitHub 赞助页面!Alyssa 不接受个人捐款,但她很乐意让您将捐款转给像软件自由组织这样的慈善机构。 (虽然也许有一天我会说服她让我为她购买 M2… ^^;;)